When Good Phone Numbers Go Bad
Hygiene is as important for data as it is for people. If a person who hasn’t showered in a while approaches someone they would like to get to know how much of a chance you think they will have of a second meeting. What do you think will happen when you try to acquire customers with dirty data? Your business will probably have as much luck as the guy who didn’t shower!
What does it mean for data to be clean or hygienic, though? If a database is considered dirty, it means that its entries are inaccurate, incomplete, or improperly formatted. So, a clean database is one in which all of the entries are up to date, entered correctly, and formatted consistently. Consistent formatting is important because it makes the data easier to deal with if the user knows what form to expect.
The impact of poor data hygiene
Phone number data hygiene in your database
Data hygiene is an important aspect of all databases, regardless of what type of information they contain. However, as we will see, data hygiene is even more important for customer telephone number data.
The Data Warehousing Institute reports that unclean data is costing U.S. businesses more than $600 billion per year. Yet, unclean data can cost businesses more than just money. It can also tarnish their reputation. When dirty data leads to marketing mistakes, many customers will take their business elsewhere and lose respect for the company.
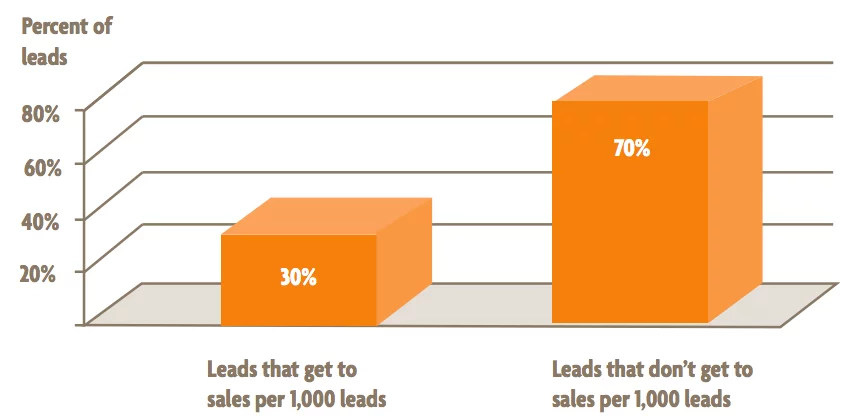
Unfortunately for business owners, marketing mistakes may cost them more than either money or their customer’s respect. Marketing mistakes resulting from bad data hygiene may cost the company itself!
Imagine a company running a telemarketing campaign. Employees call potential customers and are sometimes asked by the callee to be placed on a do-not-call list. Employees who forget to enter this request into the database or simply maintain the database poorly may compromise the company by violating the Federal Trade Commission’s Telemarketing Sales Rule. This rule states telemarketers may not call those on the Do Not Call list. Therefore, employees calling this potential customer after the original request has been made may lead their company down a path they do not want to travel.
How well do data-centric businesses keep their data clean?
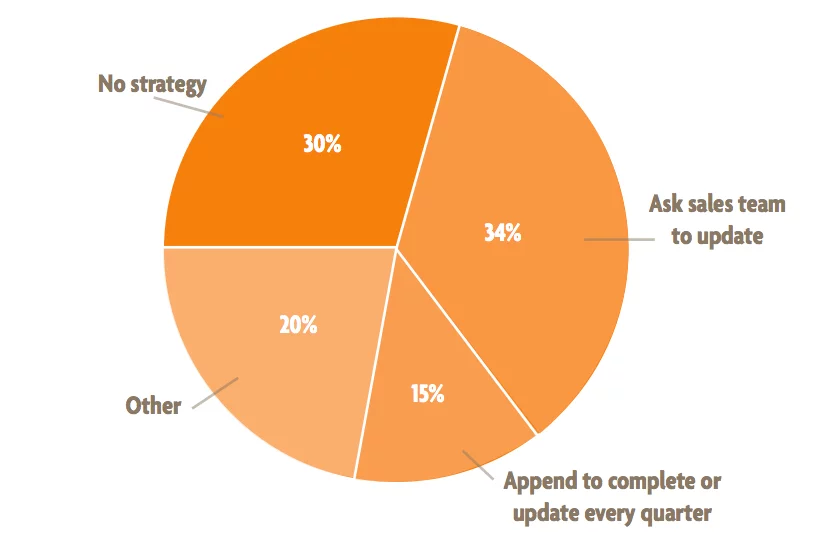
The problem of data hygiene affects all data-centric businesses. A landmark survey recently conducted by DemandGen suggests that many businesses have trouble keeping their data clean. They reported that most businesses surveyed had databases with between 10% and 40% of their records unclean. One of the major problems here is that much of the data that enters the database is unclean, to begin with. Customers may provide incorrect, inaccurate, or malformed information. This is why real-time validation is so important for businesses.
Typical information missing from the data
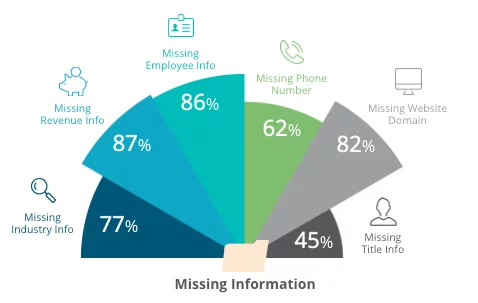
Even if the data is clean, to begin with, this does not ensure it will be clean at a later time. This idea of data getting dirtier or going bad over time is called “data decay”. Though some types of data get dirty faster than others, we’ve found through millions of validations that phone number databases generally experience this at a rate of about 2.1% of the entire database per month. That means that each month, 2.1% of the entries in the database will no longer be valid, and each year, about 22% of the entries in the database will go bad.
The situation gets worse, though! In the modern world, information is becoming increasingly widespread, making it harder to maintain accurate databases of customer information. More people today have personal telephone numbers than ever before, and this number continues to grow, so there is increasingly more data to deal with.
To make things even worse, the rate at which data decays is increasing. A recent study done by LinkedIn finds that workers are changing jobs much more often than previous generations. They predict the current generation of college graduates will change jobs twice as often as graduates did twenty years ago! Customer data stays relevant for shorter periods as workers move around. As a result, it is harder to design marketing campaigns that hit their target demographic. It doesn’t matter how well-crafted a telemarketing campaign is; if that data is bad, the message doesn’t get delivered.
Despite how seemingly hopeless this situation sounds, there are easy steps businesses can take to handle the problem of data hygiene.
Data hygiene is a big problem, and it’s worsening over time. However, following these steps and adhering to a rigorous data hygiene protocol will ensure businesses avoid the high costs and embarrassment caused by dealing with dirty data. Once businesses make data hygiene an active part of their process, dirty data will be a thing of the past.
